
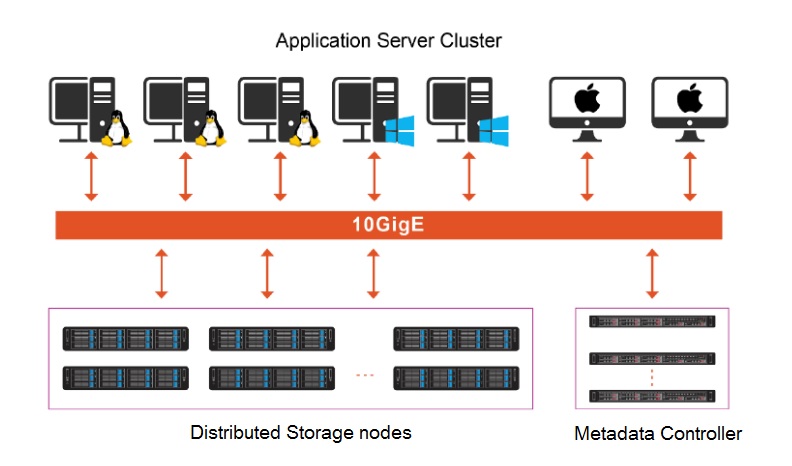
SANCluster InfinityScale Storage architecture consists of two main parts: the metadata cluster and the Distributed storage cluster. A typical system will have 3 or more storage servers, and at least one pair of metadata servers. Network options include 10 GbE ,40 GbE up to 200 Gb InfiniBand. Different from typical SAN or NAS storage, there is no controller or gateway in our system. By separating metadata from storage nodes, our solution can provide the efficient handling of either large size (>10 GB) files or small size (kb-sized) files.
1. Metadata Cluster
The metadata server manages the functions of file creation and file open in the system. The cluster has three key functions. First, it manages the metadata of the file system such as directory (tree) structure, time of creation, owner ID, access permission, and etc. Second, it develops the global namespace, allowing each application server to access the files and coordinates the data traffic between the application server cluster and the storage server cluster. Finally, it provides the management interface for the systems. Since the index and metadata information of a file usually are a few hundred bytes in size, we equip each metadata sever with two SSDs. Leveraging SSDs’ performance as a storage medium, and with the specially designed algorithm of our proprietary file system, our system can manage more than billion files. In an actual deployment of a 5 PB system, there are 18 metadata servers actively managing over 40 billion files.Separating metadata from the storage node has eliminated the system concern on file limitation under a single directory. SANCluster Storage has an actual customer case with tens of millions of files built in a single directory. And there is no limit on the number of directories in one system.
2. Distributed Storage Cluster
Storage servers (aka storage nodes) manage data storage and provide I/O services to application servers. Data is replicated and distributed across multiple storage servers. We offer theoretical support on cluster sizes of over 10,000 servers providing Exabyte (EB) level capacity and have actual deployments of more than 400 servers in one cluster.
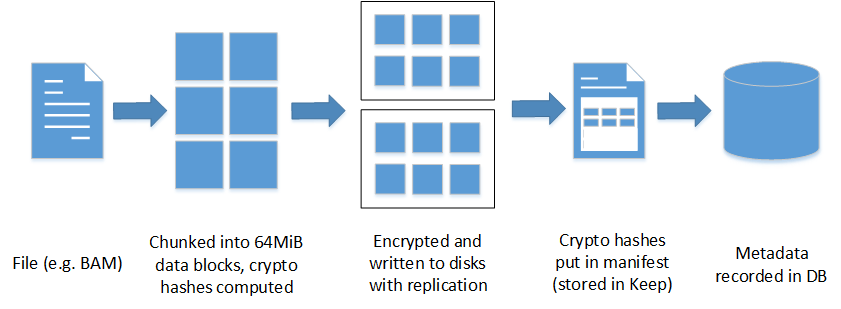
When a file is being stored, the application server will first communicate with metadata server to receive instructions on where to store the file. And then the file will be sliced up, if the file is more than 64 MB, or, if it is less than 64 MB simply stored to the storage server. The metadata server is only involved, when there is a metadata-related operation. When application servers access data, they only communicate to the metadata controller once, and access the requested data from storage servers without further interaction with metadata servers.
Application Server Cluster
By installing client-side software (a MB size driver), these application servers can access the storage cluster as a local drive. Data can be stored and shared in one single storage pool.
Multiple terminals of various operating systems such as Window, Linux, Mac, and Unix can simultaneously access the storage system. We have theoretical support on cluster sizes of 40,000 servers, with actual deployments of more than 1,000 servers in a high-performance computing site.
InfinityScale file system is a proprietary and completely POSIX-compliant cluster file system. It replicates and distributes files across nodes in the storage server cluster.
Key Functions of SANCluster InfinityScale file system is:
- Virtualizes storage resources across all available storage servers into a unified storage pool and provides a single global namespace
- Controls metadata servers to provide support on data dispatch, including metadata-intensive applications and a large amount of concurrent file access
- Manages the system’s automated self-monitoring mechanism, consistently checking system condition and performance level, it can proactively single out near-inactive stage hardware, either disks or servers, to provide high data availability, eliminating system downtime
- Provides system maintenance and upgrade
Global Namespace
Increased storage is accessible in the same location or folders. Server shared storage disks are increased under the same storage.
Hardware failure tolerance
It depends on the size of the cluster and what method customer use on data protection with redundancy. Usually a cluster can sustain normal operation with one storage server failure. Therefore, if a cluster is equipped with 16-drive nodes, a total of 16 disks can fail without cluster downtime. Similarly, with 36-drive nodes, the cluster will still be up even when 36 disks fail.
We reduce system downtime risk by using a Self-Healing / Self-Monitoring mechanism. The build-in feature detects drive performance periodically, and if the performance does not match what is expected, the system will mark the drive to be read only, will move data out, and ask for new drives for replacement. This is preemptive protection.
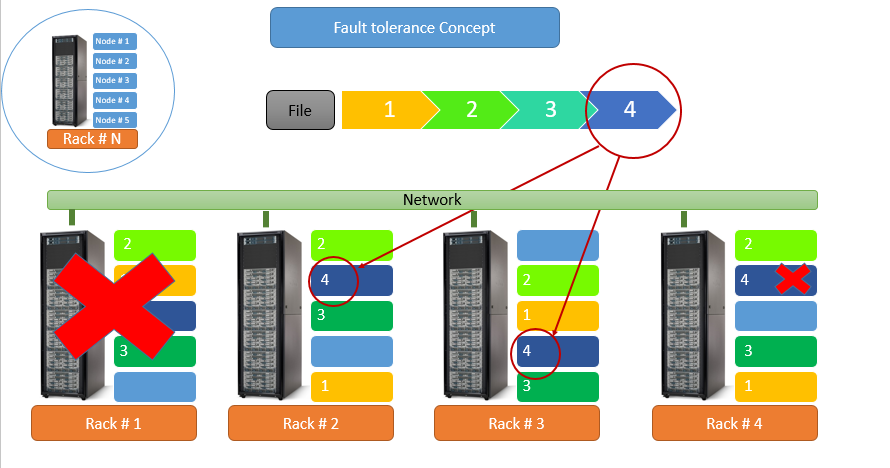
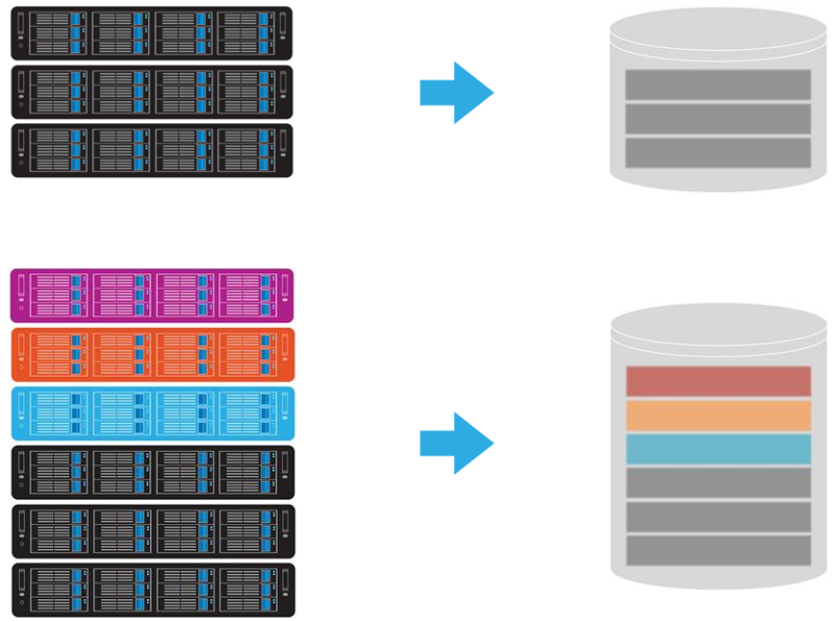
When using replica method, one file can be replicated up to 4 replicas. When having 2 replicas, system will still be up with 1 server failure in the cluster. When having 3 replicas, system will still be up with 2 server failure in the cluster. When having 4 replicas, system will still be up with 3 server failure in the cluster of minimum of 5 storage servers.
Besides the replica method, customer can chose our File-level RAID to protect the cluster for better capacity utilization. When using 2+1 File-level RAID, capacity utilization can be up to 67%. When using 4+1 File-level RAID, capacity utilization can be up to 80%. In either case, the cluster can sustain normal operation with 1 server failure.
In addition, our system offers fast rebuild times; much faster than any RAID controller. The failing drive’s data will be moved to a safe location before the next failure. Separately, replication protection provides a complete copy of data and this is used to provide additional protection. Our system supports up to 4 replications.